Detecting Abuse
Abuse is not a quantifiable phenomenon. It may not be possible to take into account all of the variables that impact the way we define abuse.
Our initial strategy involved searching for a specific type of abuse that could be easily detected using patterns of speech, like certain offensive key terms or phrases.
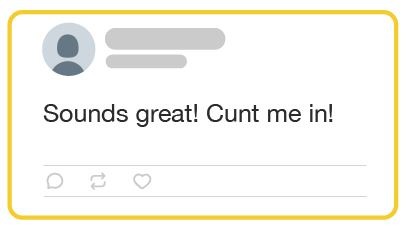
The c-word is an offensive term for vagina or vulva. Because this term scores high on measures of offensiveness and toxicity, it will almost always be counted as abusive, even when it appears as a typo.
Finding abusive tweets using keywords is difficult because aggressive language on Twitter is very common. Written language is complex and patterns of speech are constantly evolving in the short form publications you find on Twitter.
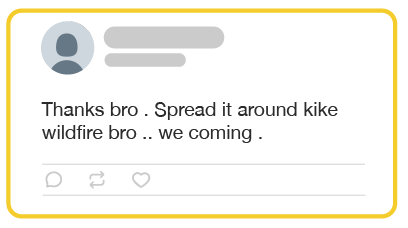
“Kike” is a slur used to refer to Jewish people. It’s an extremely offensive term, but it appears often as a typo on Twitter. It’s also a nickname used frequently in Latin America.
We need to find away to teach our machines to understand context. A manual user on Twitter has the ability to click back and forth throughout a conversation. Using only keywords to flag abuse gives our machine only a very limited understand of the language that it analyzes, because it is not able to analyze the context that the tweet is operating in.
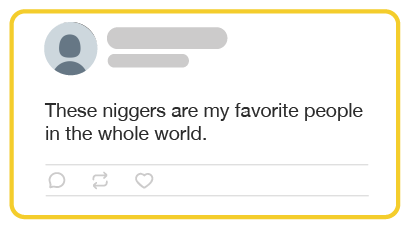
The n-word is a reclaimed racial slur, that can be extremely offensive depending on who uses it. There is no reliable way to determine when this term is appropriate.
Our bot uses racial slurs that have not been reclaimed to flag tweets for classification. The model we use to classify tweets as abusive is a combination of models found in our research.